Explainable Vision-Language Model Benchmark for Surgery — WACV 2026
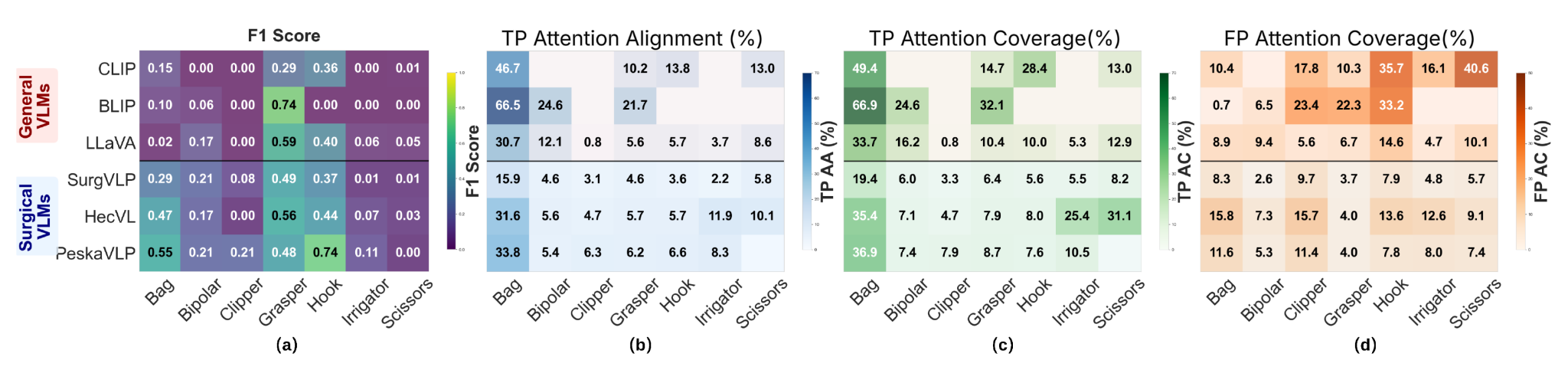
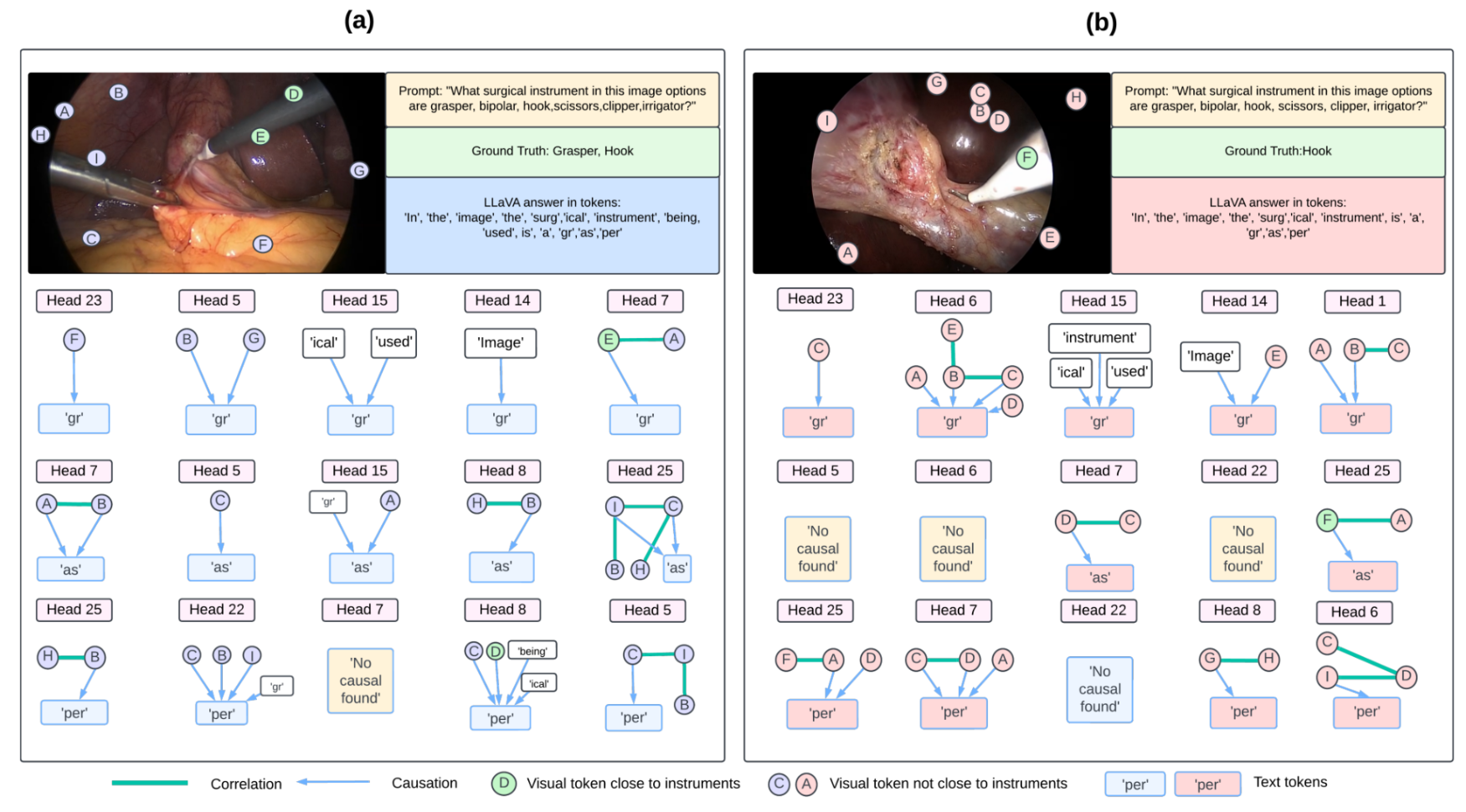
SurgXBench introduces the first explainability-driven benchmark for Vision-Language Models in robotic surgery. We evaluate general & surgical VLMs for instrument & action recognition, visualize model reasoning using Grad-CAM and causal graphs, and introduce attention-alignment metrics to assess whether models rely on clinically meaningful visual cues. Results reveal a gap between accuracy and reasoning, motivating the need for more grounded supervision in surgical VLMs.
Innovations in digital intelligence are transforming robotic surgery with more informed decision-making. Real-time awareness of surgical instrument presence and actions (e.g., cutting tissue) is essential for such systems. Yet, despite decades of research, most machine learning models for this task are trained on small datasets and still struggle to generalize. Recently, Vision-Language Models (VLMs) have brought transformative advances in reasoning across visual and textual modalities. Their unprecedented generalization capabilities suggest great potential for advancing intelligent robotic surgery. However, surgical VLMs remain under-explored, and existing models show limited performance, highlighting the need for benchmark studies to assess their capabilities and limitations and to inform future development. To this end, we benchmark the zero-shot performance of several advanced VLMs on two public robotic-assisted laparoscopic datasets for instrument and action classification. Beyond standard evaluation, we integrate explainable AI to visualize VLM attention and uncover causal explanations behind their predictions. This provides a previously underexplored perspective in this field for evaluating the reliability of model predictions. We also propose several explainability analysis-based metrics to complement standard evaluations. Our analysis reveals that surgical VLMs, despite domain-specific training, often rely on weak contextual cues rather than clinically relevant visual evidence, highlighting the need for stronger visual and reasoning supervision in surgical applications.
@inproceedings{cheng2026surgxbench,
title = {SurgXBench: Explainable Vision-Language Model Benchmark for Surgery},
author = {Cheng, Jiajun and Zhao, Xianwu and Liu, Sainan and Yu, Xiaofan and
Prakash, Ravi and Codd, Patrick and Katz, Jonathan and Lin, Shan},
booktitle = {WACV},
year = {2026}
}
Contact: Shan Lin
Lab Address:
Goldwater Center 381
650 E. Tyler Mall
Tempe, AZ 85287-5706
© 2025 MARGIN Lab. All rights reserved.





